I have a partitioned table for some application logging. A few years ago, I partitioned the table with one partition per month. As we near 2016, its time for me to add partitions for the new year. The partitioned table has, as its last two partitions, the partition for December 2015 and a partition using MAXVALUE. I never plan on having any data in the MAXVALUE partition. It is just there for making SPLIT PARTITION operations easier.
In the past, I would add partitions with commands similar to the following:
ALTER TABLE usage_tracking
SPLIT PARTITION usage_tracking_pmax AT (TO_DATE('02/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS))
INTO (PARTITION usage_tracking_p201601, PARTITION usage_tracking_pmax);
ALTER TABLE usage_tracking
SPLIT PARTITION usage_tracking_pmax AT (TO_DATE('03/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS'))
INTO (PARTITION usage_tracking_p201602, PARTITION usage_tracking_pmax);
The SQL statements above will split the MAXVALUE partition into two partitions. There are 12 such commands, one for each month.
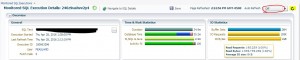
This year, when I tried to run the script for 2016 in a non-production environment, I was surprised to find these commands took about 30 minutes for each to complete. In previous years, they completed in seconds. Remember that USAGE_TRACKING_PMAX is empty so no data needs to be moved into an appropriate partition.
In analyzing the activity of my session performing the SPLIT, I could clearly see db file wait events which were tracked to this partitioned table. It was obvious that the SPLIT operation was reading the max partition, even though it was empty.
Previous years worked fine, but this database was recently upgraded to Oracle 12c. I found information on how to perform a fast split partition operation in MOS Note 1268714.1 which says this applies to Oracle 10.2.0.3 and higher, but I did not have any issues in 11.2.0.4. It was probably just dumb luck and I don’t have an 11g database to check this out on as all of mine have been upgraded. As such, rather than focusing on what changed, I’ll just address the problem and get on with my day.
Per the MOS note, to perform a fast split partition on this empty partition, I need to make sure that I have stats on the empty partition.
I confirmed that the NUM_ROWS was 0 for this empty partition. So I didn’t have to calculate stats on the partition. My first SPLIT PARTITION operation was very fast, just a few seconds. The partition was empty and Oracle knew it. What surprised me was that the new partition, USAGE_TRACKING_P201601 and USAGE_TRACKING_PMAX went to NULL values for statistics. This meant that performing the SPLIT PARTITION operation for the second new partition would take a long time. Here is an example of what I mean. First, we can see 0 rows in the max value partition.
SQL> select num_rows from dba_tab_partitions
2 where partition_name='USAGE_TRACKING_PMAX';
NUM_ROWS
----------
0
Now I’ll split that partition.
SQL> ALTER TABLE usage_tracking
2 SPLIT PARTITION usage_tracking_pmax AT ( TO_DATE('02/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS') )
3 INTO (PARTITION usage_tracking_p201601, PARTITION usage_tracking_pmax);
Table altered.
Elapsed: 00:00:03.13
Notice now that the last two partitions now have no stats.
SQL> select num_rows from dba_tab_partitions
2 where partition_name='USAGE_TRACKING_PMAX';
NUM_ROWS
----------
SQL> select num_rows from dba_tab_partitions
2 where partition_name='USAGE_TRACKING_P201601';
NUM_ROWS
----------
With no stats, the next split partition to create the February 2016 partition takes a long time.
SQL> ALTER TABLE nau_system.usage_tracking
2 SPLIT PARTITION usage_tracking_pmax AT (TO_DATE('03/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS'))
3 INTO (PARTITION usage_tracking_p201602, PARTITION usage_tracking_pmax);
Table altered.
Elapsed: 00:27:41.09
As the MOS note says, we need the stats on the partition to perform a fast split operation. The solution is to calculate stats on the partition, and then use one ALTER TABLE command to create all the partitions at once.
BEGIN
DBMS_STATS.gather_table_stats (tabname=>'USAGE_TRACKING',
partname => 'USAGE_TRACKING_PMAX',
granularity => 'PARTITION');
END;
/
ALTER TABLE usage_tracking
SPLIT PARTITION usage_tracking_pmax INTO
(PARTITION usage_tracking_p201601 VALUES LESS THAN (TO_DATE('02/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS')),
PARTITION usage_tracking_p201602 VALUES LESS THAN (TO_DATE('03/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS')),
PARTITION usage_tracking_p201603 VALUES LESS THAN (TO_DATE('04/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS')),
PARTITION usage_tracking_p201604 VALUES LESS THAN (TO_DATE('05/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS')),
PARTITION usage_tracking_p201605 VALUES LESS THAN (TO_DATE('06/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS')),
PARTITION usage_tracking_p201606 VALUES LESS THAN (TO_DATE('07/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS')),
PARTITION usage_tracking_p201607 VALUES LESS THAN (TO_DATE('08/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS')),
PARTITION usage_tracking_p201608 VALUES LESS THAN (TO_DATE('09/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS')),
PARTITION usage_tracking_p201609 VALUES LESS THAN (TO_DATE('10/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS') ),
PARTITION usage_tracking_p201610 VALUES LESS THAN (TO_DATE('11/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS') ),
PARTITION usage_tracking_p201611 VALUES LESS THAN (TO_DATE('12/01/2016 00:00:00','MM/DD/YYYY HH24:MI:SS') ),
PARTITION usage_tracking_p201612 VALUES LESS THAN (TO_DATE('01/01/2017 00:00:00','MM/DD/YYYY HH24:MI:SS') ),
PARTITION usage_tracking_pmax);
If I would have left the script to performing 12 individual SPLIT PARTITION operations, then I would have needed to recalculate stats on the max partition between each one. Using one command was more efficient.